How to View the Latest Database Schema Post-Migrations
1 How to Get the Current Database Schema After Migrations
When a database schema changes frequently, the project eventually accumulates a large number of migration files.
Each migration covers only a single change - adding a column, modifying its type, renaming a table, dropping an index, and so on.
These migrations may also be implemented differently - some as raw SQL, others in Go code.
Over time they form a long chain, and it becomes non-trivial to understand the actual state of the database at any given moment.
This is especially true if the project evolves quickly or is maintained by several teams.
Things get even more complicated in a multi-service architecture, where each service has its own schema and its own set of migrations.
It’s easy to lose track of which migration belongs to which schema - and understanding the current structure of each database becomes a challenge.
Input context:
The services are written in Go, and each service has its own independent migrations implemented both in SQL and in Go — each targeting its own schema. All services share a single PostgreSQL database and use Goose for migrations.
2 Структура сервиса
All migrations for each service are stored in its own migrations directory:
❯ tree migrations
migrations
├── 20250917161808_tasks_create_table.sql
├── 20250920121003_add_priority_column.go
├── 20250920143353_add_index_to_tasks.sql
├── 20250922201310_migrate_task_status.go
├── 20250921151515_update_task_constraints.sql
...Migration files may be written either in SQL or in Go, and are defined in a format compatible with goose.
Each service exposes a MigrationsSchema — the name of the schema its migrations belong to — and a MigrationsFS, an embedded file system (embed.FS) that contains all migration files for that service:
var (
//go:embed migrations/*
MigrationsFS embed.FS
MigrationsSchema = "taskrepository"
)3 Migrator structure
Since the structure and format of migrations are the same across all services, we can implement a shared function to apply them.
Input: a database connector, the schema name, and the migration files.
func Migrate(ctx context.Context, logger *slog.Logger, dbHandler *sql.DB, schema string, migrationsFS fs.FS) error {
_, err := dbHandler.ExecContext(ctx, "CREATE SCHEMA IF NOT EXISTS "+schema)
if err != nil {
return err
}
store, err := database.NewStore(goose.DialectPostgres, schema+".goose_db_version")
if err != nil {
return err
}
migrationsFS, err = fs.Sub(migrationsFS, "migrations")
if err != nil {
return err
}
provider, err := goose.NewProvider("", dbHandler, migrationsFS,
goose.WithStore(store), goose.WithVerbose(true), goose.WithLogger(sharedlogginggoose.NewGooseLogger(logger)))
if err != nil {
return err
}
migrations, err := provider.Up(ctx)
if err != nil {
return err
}
logger.InfoContext(ctx, "migrations applied", "migrations", migrations)
return nil
}Key points:
- If the target schema does not exist, it must be created — otherwise
goosewon’t be able to create thegoose_db_versiontable. migrationsFSinitially points to themigrationsdirectory. However,gooseexpects the migration files to be located in the current directory ("."). Therefore,fs.Subis used to switch the working directory.
4 Schema Generator Structure
goose can apply migrations directly to a database — all it needs are the database connection parameters and the migration files.
To obtain the database schema, we can use the pg_dump utility. This only requires specifying the database connection parameters and the output format.
Example command: pg_dump --schema-only --format=plain --no-owner --username=postgres --dbname=testdb.
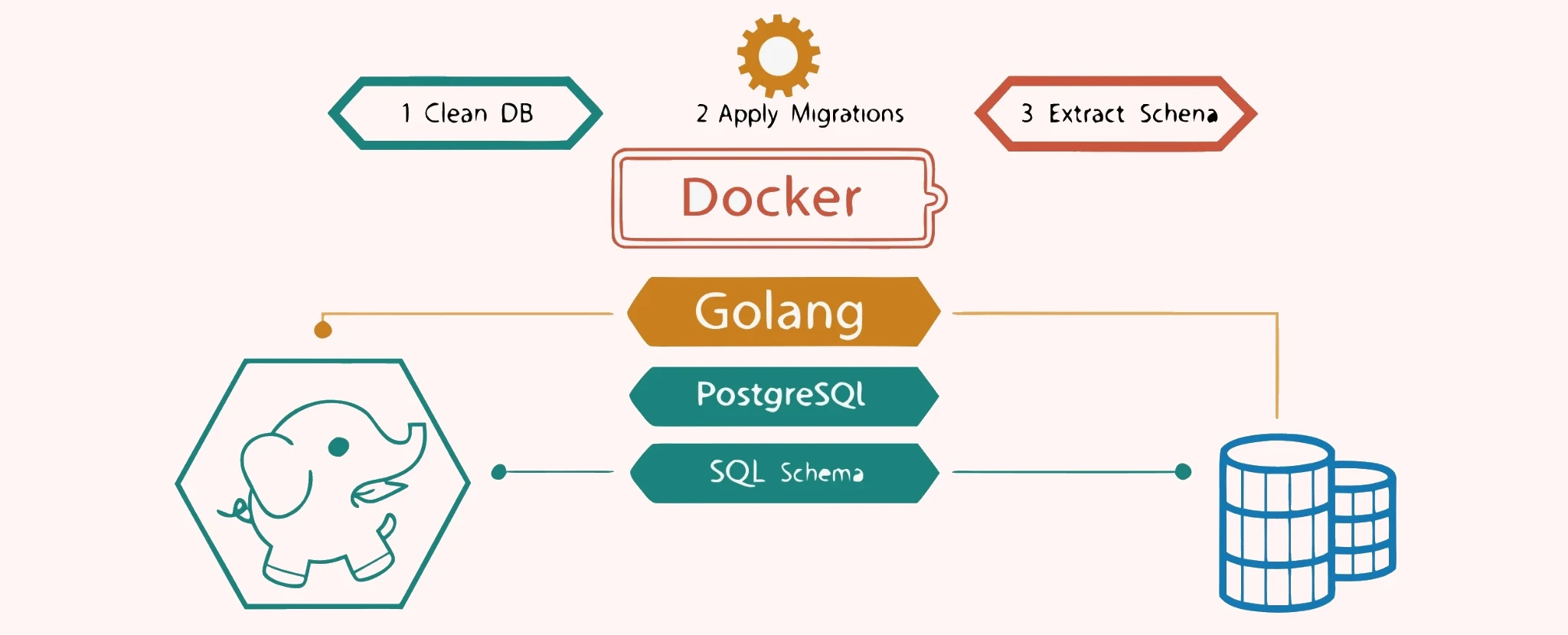
The schema generation process consists of four steps:
- Launch a clean
PostgreSQLinstance inDocker. - Apply the migrations to the database using
goose. - Extract the database schema with
pg_dump. - Save the resulting schema to a file.
In code, this is implemented as follows: we first gather the MigrationsSchema and MigrationsFS for each service, and then save the current schema:
func run() error {
params := []migrationParam{
{schema: taskrepository.MigrationsSchema, migrationsFs: taskrepository.MigrationsFS},
{schema: userrepository.MigrationsSchema, migrationsFs: userrepository.MigrationsFS},
// ...
}
for _, param := range params {
if err := saveSchema(param); err != nil {
return err
}
}
return nil
}The saveSchema function launches a PostgreSQL container, applies the migrations, and saves the resulting schema to a file:
func saveSchema(param migrationParam) error {
ctx := context.Background()
req := testcontainers.ContainerRequest{ //nolint:exhaustruct
Image: "postgres:18-alpine",
Env: map[string]string{"POSTGRES_PASSWORD": "pass", "POSTGRES_DB": "testdb"},
ExposedPorts: []string{"5432/tcp"},
WaitingFor: wait.ForListeningPort("5432/tcp"),
}
postgresC, err := testcontainers.GenericContainer(ctx, testcontainers.GenericContainerRequest{ //nolint:exhaustruct
ContainerRequest: req,
Started: true,
})
if err != nil {
return err
}
defer func() { _ = postgresC.Terminate(ctx) }()
host, _ := postgresC.Host(ctx)
port, _ := postgresC.MappedPort(ctx, "5432")
dsn := fmt.Sprintf("postgres://postgres:pass@%s/testdb?sslmode=disable", net.JoinHostPort(host, port.Port()))
dbHandler, err := shareddatabase.New(ctx, dsn)
if err != nil {
return err
}
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
if err := sharedsqlmigrator.Migrate(ctx, logger, dbHandler, param.schema, param.migrationsFs); err != nil {
return err
}
cmd := []string{
"pg_dump",
"--schema-only",
"--format=plain",
"--no-owner",
"--username=postgres",
"--dbname=testdb",
"--restrict-key=000000000000000000000000000000000000000000000000000000000000000",
}
_, r, err := postgresC.Exec(ctx, cmd, exec.Multiplexed())
if err != nil {
return err
}
f, err := os.Create(fmt.Sprintf("./docs/sqlschema/%s.sql", param.schema))
if err != nil {
return err
}
defer func() { _ = f.Close() }()
_, err = io.Copy(f, r)
if err != nil {
return err
}
return nil
}In this implementation:
- We start a clean
PostgreSQLinstance inDocker, using a lightweightAlpine-based image.testcontainersis used to manage Docker containers. - We construct the
DSNand apply the migrations. - Inside the container, we run
pg_dumpwith the required parameters. The output is sent tostdout. To ensure the output is clean and free of service-related binary headers, theMultiplexedoption must be specified. - The output is then copied from the container into a file.
Example of data from the resulting schema:
-- ...
--
-- Name: tasks; Type: TABLE; Schema: taskrepository; Owner: -
--
CREATE TABLE taskrepository.tasks (
task_id uuid NOT NULL,
request_id uuid NOT NULL,
created_at timestamp with time zone NOT NULL,
status text NOT NULL,
data jsonb NOT NULL
);
--
-- Name: tasks tasks_pkey; Type: CONSTRAINT; Schema: taskrepository; Owner: -
--
ALTER TABLE ONLY taskrepository.tasks
ADD CONSTRAINT tasks_pkey PRIMARY KEY (task_id);
--
-- Name: idx_tasks_incomplete; Type: INDEX; Schema: taskrepository; Owner: -
--
CREATE INDEX idx_tasks_incomplete ON taskrepository.tasks USING btree (status) WHERE (status <> 'completed'::text);
-- ...As a result, we obtain an up-to-date SQL schema for each service.
The schemas are stored within the project and updated whenever new migrations are added.
There’s no longer a need to mentally apply all migrations to understand the current database structure.
Additionally, when developing new migrations, you can immediately see the final state of the schema and verify that there are no errors during its application.