Как получить актуальную структуру БД после миграций
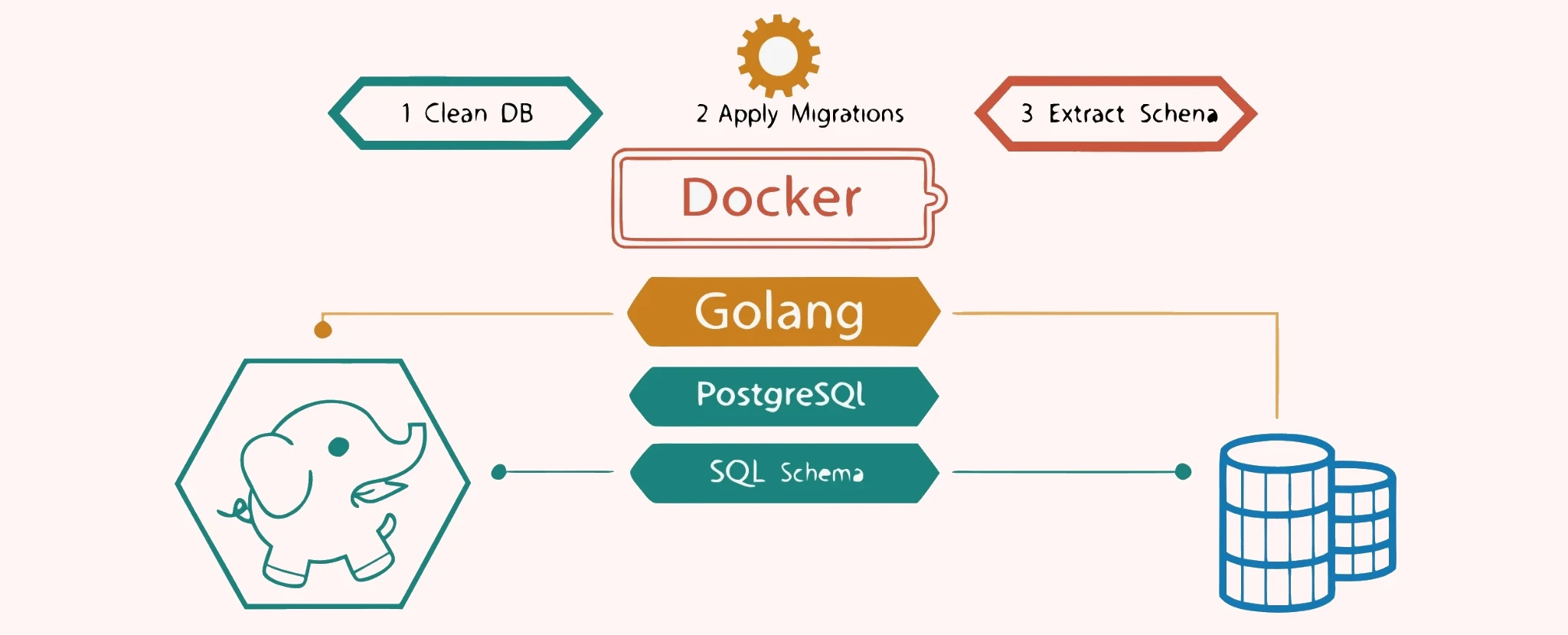
1 Как получить актуальную структуру БД после миграций
При частых изменениях структуры базы данных со временем накапливается множество файлов миграций.
Каждая из них описывает только отдельное изменение — добавить колонку, изменить тип колонки, переименовать таблицу, удалить индекс и т.д.
Они могут быть реализованы по-разному - где-то в чистом SQL, где-то в Go-коде.
Вместе они образуют длинную цепочку, и уже не так просто понять, как выглядит база в итоге.
Особенно если проект развивается быстро или над ним работает несколько команд.
Ситуация усложняется, если в проекте много сервисов, и у каждого своя схема и свой набор миграций.
Знания о том, какая миграция к какой схеме относится, могут легко запутаться, и понять актуальную структуру каждой схемы становится сложнее.
Чтобы не тратить время на разбор всех схем и миграций вручную, написал небольшую утилиту, которая для каждого сервиса автоматически генерирует актуальную SQL-схему.
Входные данные:
Сервисы написаны на Go, у каждого сервиса свои независимые миграции на sql и на go для собственной схемы. Все сервисы используют одну базу данных PostgreSQL с goose.
2 Структура сервиса
Все миграции каждого сервиса находятся в директории migrations:
❯ tree migrations
migrations
├── 20250917161808_tasks_create_table.sql
├── 20250920121003_add_priority_column.go
├── 20250920143353_add_index_to_tasks.sql
├── 20250922201310_migrate_task_status.go
├── 20250921151515_update_task_constraints.sql
...Файлы миграций могут быть как на SQL, так и на Go, и описаны в формате, который понимает goose.
Каждый сервис содержит MigrationsSchema — название схемы, к которой относятся миграции, и MigrationsFS — встроенную файловую систему (embed.FS), включающую все файлы миграций сервиса:
var (
//go:embed migrations/*
MigrationsFS embed.FS
MigrationsSchema = "taskrepository"
)3 Структура мигратора
Поскольку структура и формат миграций одинаковые для всех сервисов, можно написать общую функцию для применения миграций.
Входные данные: коннектор к БД, название схемы, файлы миграции.
func Migrate(ctx context.Context, logger *slog.Logger, dbHandler *sql.DB, schema string, migrationsFS fs.FS) error {
_, err := dbHandler.ExecContext(ctx, "CREATE SCHEMA IF NOT EXISTS "+schema)
if err != nil {
return err
}
store, err := database.NewStore(goose.DialectPostgres, schema+".goose_db_version")
if err != nil {
return err
}
migrationsFS, err = fs.Sub(migrationsFS, "migrations")
if err != nil {
return err
}
provider, err := goose.NewProvider("", dbHandler, migrationsFS,
goose.WithStore(store), goose.WithVerbose(true), goose.WithLogger(sharedlogginggoose.NewGooseLogger(logger)))
if err != nil {
return err
}
migrations, err := provider.Up(ctx)
if err != nil {
return err
}
logger.InfoContext(ctx, "migrations applied", "migrations", migrations)
return nil
}Общие моменты:
- Если нужной схемы нет, то её нужно создать. Иначе
gooseне сможет создать таблицуgoose_db_version. migrationsFSизначально указывает на директориюmigrations.gooseже ожидает, что миграционные файлы будут в текущей директории ("."). Поэтому используетсяfs.Subдля смены директории.
4 Структура генератора схем
goose умеет применять миграции с БД. Для этого нужно только указать параметры подключения к БД и данные миграции.
Получить схему БД можно с помощью утилиты pg_dump. Для этого нужно только указать параметры подключения к БД и формат вывода.
Пример команды: pg_dump --schema-only --format=plain --no-owner --username=postgres --dbname=testdb.
Процесс генерации схемы сводится к четырем шагам:
- Поднять чистую базу PostgreSQL в докере.
- Применить к базе миграции через goose.
- Получить схему БД через
pg_dump. - Сохранить схему в файл.
В коде это реализовано следующим образом: сначала собираем для каждого сервиса его MigrationsSchema и MigrationsFS, а затем сохраняем актуальную схему:
func run() error {
params := []migrationParam{
{schema: taskrepository.MigrationsSchema, migrationsFs: taskrepository.MigrationsFS},
{schema: userrepository.MigrationsSchema, migrationsFs: userrepository.MigrationsFS},
// ...
}
for _, param := range params {
if err := saveSchema(param); err != nil {
return err
}
}
return nil
}Функция saveSchema поднимает контейнер с PostgreSQL, применяет миграции и сохраняет схему в файл:
func saveSchema(param migrationParam) error {
ctx := context.Background()
req := testcontainers.ContainerRequest{ //nolint:exhaustruct
Image: "postgres:18-alpine",
Env: map[string]string{"POSTGRES_PASSWORD": "pass", "POSTGRES_DB": "testdb"},
ExposedPorts: []string{"5432/tcp"},
WaitingFor: wait.ForListeningPort("5432/tcp"),
}
postgresC, err := testcontainers.GenericContainer(ctx, testcontainers.GenericContainerRequest{ //nolint:exhaustruct
ContainerRequest: req,
Started: true,
})
if err != nil {
return err
}
defer func() { _ = postgresC.Terminate(ctx) }()
host, _ := postgresC.Host(ctx)
port, _ := postgresC.MappedPort(ctx, "5432")
dsn := fmt.Sprintf("postgres://postgres:pass@%s/testdb?sslmode=disable", net.JoinHostPort(host, port.Port()))
dbHandler, err := shareddatabase.New(ctx, dsn)
if err != nil {
return err
}
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
if err := sharedsqlmigrator.Migrate(ctx, logger, dbHandler, param.schema, param.migrationsFs); err != nil {
return err
}
cmd := []string{
"pg_dump",
"--schema-only",
"--format=plain",
"--no-owner",
"--username=postgres",
"--dbname=testdb",
"--restrict-key=000000000000000000000000000000000000000000000000000000000000000",
}
_, r, err := postgresC.Exec(ctx, cmd, exec.Multiplexed())
if err != nil {
return err
}
f, err := os.Create(fmt.Sprintf("./docs/sqlschema/%s.sql", param.schema))
if err != nil {
return err
}
defer func() { _ = f.Close() }()
_, err = io.Copy(f, r)
if err != nil {
return err
}
return nil
}В этой реализации:
- Поднимаем чистую базу
PostgreSQLв докере на базе легковесногоAlpine-образа. Для работы с докером используемtestcontainers. - Формируем
dsnи применяем миграции. - В докере запускаем команду
pg_dumpс параметрами. Результат будет передан вstdout. Важно, чтобы вывод был чистым без служебных бинарных заголовков нужно указать опциюMultiplexed. - Копируем вывод из контейнера в файл.
Пример данных из полученной схемы:
-- ...
--
-- Name: tasks; Type: TABLE; Schema: taskrepository; Owner: -
--
CREATE TABLE taskrepository.tasks (
task_id uuid NOT NULL,
request_id uuid NOT NULL,
created_at timestamp with time zone NOT NULL,
status text NOT NULL,
data jsonb NOT NULL
);
--
-- Name: tasks tasks_pkey; Type: CONSTRAINT; Schema: taskrepository; Owner: -
--
ALTER TABLE ONLY taskrepository.tasks
ADD CONSTRAINT tasks_pkey PRIMARY KEY (task_id);
--
-- Name: idx_tasks_incomplete; Type: INDEX; Schema: taskrepository; Owner: -
--
CREATE INDEX idx_tasks_incomplete ON taskrepository.tasks USING btree (status) WHERE (status <> 'completed'::text);
-- ...В итоге для каждого сервиса мы получаем актуальную SQL-схему.
Схемы хранятся в проекте и обновляется при добавлении миграций.
Больше не нужно мысленно применять все миграции, чтобы понять текущую структуру данных.
Кроме того, при разработке новых миграций сразу видно итоговое состояние схемы и можно проверить, нет ли ошибок при её применении.